Algovincian's NPR and Other Junk (2022)
 algovincian
Posts: 2,621
algovincian
Posts: 2,621
Since several people have asked lately about the progress with regards to my Non-Photorealistic Rendering algorithms (and possibly releasing a product here in the DAZ3D store), it seemed like it may be worthwhile making a new thread to discuss it. In this thread, you'll find info/discussion about the status of my NPR work, as well as a place to post some new NPR styles (images > words) and a few other non-NPR projects (SBH, dForce, animation/video, etc.). It'll be a dump for DS related stuff in general.
Those of you that have been following along are already aware that the output the algos produce is the result of a long, complex process. The fact that, at its heart, it's been an exercise in automated systems integration, makes it difficult (if not impossible) to neatly package up, distribute, and install on other peoples' machines due to the sheer number of components, licensing considerations, etc.
In an effort to find a solution to these limitations, I've been exploring my own flavor of Neural Style Transfer (NST) networks as a replacement for the existing process. The idea is that once completed, such a network could be distributable.
With NSTs, normally there is one style image (like a Monet painting for example) and a subject image (like a photo of your house). The style is transferred from the painting to the photo - in this example your house would be painted in Monet's style. This is accomplished with the help of a pre-trained Convolutional Neural Network (CNN) and the iterative minimizing of a loss function.
IMHO, while the results from such networks are interesting, they're limited and leave much to be desired. The idea here is to incorporate some old-school supervised training into the mix, as well as take advantage of the added info 3D rendering provides to improve the networks:
1. Typical NSTs don't utilize explicit input/output image pairs for supervised training (a picture of a particular mountain and a corresponding painting of that mountain). For obvious reasons, large numbers of these pairs simply don't exist. However, the current algos make it possible to create large datasets of these input/output image pairs.
2. The network has access to much more information than a single 2D image can provide at the input thanks to the analysis passes rendered out of DS (separate masks, color, shading, shadows, ambient occlusion, fresnel, etc.).
What I've been doing is rendering thousands of matched pairs of input/output to be used in the supervised training of such a network. Unfortunately, I apparently suck, and have failed at designing such a network as of yet lol.
It's no surprise that this has proven to be challenging. I'm continuing to look at several problematic realities including the scale of the structures involved (not looking at single pixels), the complexity of the relationships between the input/output, the complexity of both the input layer/overall network, the fact that the output is too random (not deterministic enough due to the iterative stroking, etc. used in the current algos), etc.
So that's what I've been doing, where I'm at, and where I'm headed with regards to a potential NPR product. Will it ultimately be successful? Who knows.
Anyway, this long-ass post needs some pictures to go along with all the words, so here's a dump of the output from last night's batch (a new black and white style):
Looking through this batch quickly, there definitely seems to be some issues that need addressing. I'll come back and look again with fresh eyes after a few days have passed before making changes to the code, though.


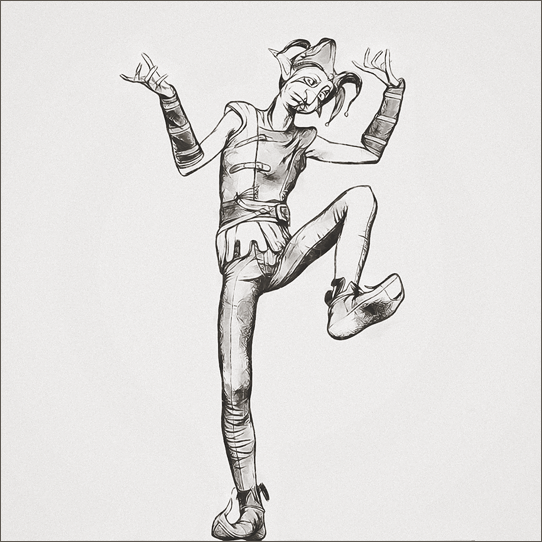


















- Greg
Daz 3D is part of 
Connect
DAZ Productions, Inc.
7533 S Center View Ct #4664
West Jordan, UT 84084
Licensing Agreement | Terms of Service | Privacy Policy | EULA
© 2024 Daz Productions Inc. All Rights Reserved.
Comments
Wow, awesome!
I haven't been following your work and I understood maybe a third of what you wrote
but those images look great! They remind me of illustrations from older childrens books (like Alice in Wonderland) and at first sight I mistook them for hand drawings.
Looking at them closer I can see that they are CGI, but they don't have that unpleasant "Photoshop Filter" look that some NPR's tend to have.
@algovincian , Superb Images like always !!
I`m curious how much time needed for processing one image ?
And if OK to ask , do you have any rough calculation about price per image cost ( electricty - hardware - software`s licence used etc) ?
Thanks
Thanks @Hylas - I know exactly what you're saying about the filtered look. There's nothing wrong with it, but it's instantaneously recognizable and I'd very much like to produce something more. All the techno-babble was basically just a description of the lengths I've been going to and hoops I'm willing to jump through to try and make it happen.
@juvesatriani - Sure. It's hard to seperate out an exact dollar amount since I have many computers chewing on many different problems all the time, but I can try to give you a feel for what hardware was used to do what and the times involved.
It all starts with rendering out the analysis passes in DS - here's a screencap of the interface for the script I wrote to automate that process:
Using the first image in the OP as an example, it looks like the 8 passes took about 15 minutes to render a couple of weeks ago using 3DL in DS on a box with a 5600x:
I checked and that scene had about 143K polies. A decent chunk of that time is spent iterating through every material for every node in the scene, analyzing those mats (which were Iray), and setting appropriate parameter values for the various custom 3DL shaders applied during each of the analysis passes. How long this step takes is obviously scene dependent (the number of nodes/mats, whether or not there's transmapped geo, HD geo, etc.).
The 8 images rendered by DS during this step are all roughly 2 megapixels (1440x1440 in this case since they were square). The output after the algos are run is around 20 megapixels and includes numerous intermediate image files, as well as a bunch of finished styles. As you can see, there's a lot of data written to the output directory for each set of analysis passes processed:
One of the ways that line thickness is controlled is through resolution. Processing smaller images results in correspondingly thicker lines. For reasons not worth getting into, the algos are tuned/optimized to produce 20 megapixel output, and that is essentially fixed. So in order to get thicker lines, the size of the subject in the analysis passes must be smaller.
I wrote a little utility script that resizes each of the analysis passes to 720x720, and then lumps 4 of them together to get back to the original 1440x1440 (which is the required resolution of analysis passes used as input to the algos):
In this case, it gave me an opportunity to quickly tweak some variations of the Z-Depth pass without having to re-render anything in DS. These changes in the Z-Depth effect the resulting output and they all get processed at the same time by the algos so they can be compared and the best chosen. Alternatively, 4 completely different sets of analysis passes can be combined into 1 new set and processed at the same time, which obviously saves time.
So how long does it take for the algos to process a set of analysis passes (which may really be 4 scenes)? It usually takes about an hour on an old dual core i5.
As a further note, I started working on this stuff last century (literally), so many of the software components integrated into the system are old, 32 bit, and single threaded. Some were written by me and can be updated, but many were not and can't be updated.
Because of how everything evolved over time throughout the years, the algos require very little system RAM and no video card. As a result, I've gotten in the habit of buying Dell refurbs from the corporate world. The specs of what's available have changed over the years, but they usually can be had for around $150. They don't come with monitors or video cards so they don't require much juice. They all just become part of the network - I just remote into them and give them their marching orders.
As far as software used that wasn't written by me, there's an old version of Photoshop CS2 (with some plugins) and an old version of HDR processing software Photomatix Pro 3.2. I believe the license for CS2 cost me about $600 back in 2005, and I think Photomatix was about $100 when I bought it.
This older version of Photomatix is great because it provides a command line interface (I'm not sure newer versions do), which allows one to script it using something like the following (VBScript):
Set oShell = WScript.CreateObject("WScript.Shell")
oShell.CurrentDirectory = "c:\progra~2\photom~1"
theCommand = "PhotomatixCL -1 -bi 8 -md -s tif -d " & " 01.jpg 02.jpg 03.jpg"
oShell.run theCommand, 1, 1
Set oShell = Nothing
Automation is really the key to everything, with VBScript being used to control the whole show (including Photoshop and other software I've written). It opens up a whole new world and allows you to think about things in a completely different way.
Anyway, sorry for the book, but I wanted to provide as much info as possible while I'm able. Hope this answers your question(s).
- Greg
The processing times discussed in answer to @juvesatriani's questions last week included the rendering of many different styles in addition to the B&W already shown. Here's another style with some color (the same 21 scenes posted last week for comparison's sake):
- Greg
Absolutely gorgeous work algovincian! Both the BW and color versions are great. Love the clean illustrated look!
There's definitely some issues that need addressing, but it's tricky because any changes made to the algos in order to correct one image will effect the way that every image is rendered, if you know what I mean.
Anyway, thanks for taking the time to comment, @SapphireBlue. It's always nice to hear that people enjoy the results - it's much appreciated.
- Greg
Bad thread title! This is not junk!!!!! Fascinating art work!
Deceiving title.
@algovincian , thanks for detail explanation !!!. I`ll try decipher in Hobbit version from yours techniques to create multipass output .
Something I`m keep seeing is Fresnel ( in yours and Line9000K ) what exactly they doing if you dont mind give me explanations
Thank again
@barbult & @jag11 - Well, my pathetic attempts at getting a new network to converge so a product can actually be released have kind of been junk lol. In all seriousness though, thanks for taking the the time to look and comment. Motivation comes and goes, and other peoples' interest definitely helps keep me going when new ideas/solutions are hard to come by.
In this context, Fresnel refers to the fact that the amount of reflectance is a function of not only the material, but also the viewing angle. In the real world if you're standing in a lake, when you look straight down at the water's surface there is limited reflection and you can see through to the botttom. As you lift your head up and look more towards the horizon (changing the viewing angle), the water reflects more and you see less of the bottom.
Taking the simple case of a sphere, this means that the edges of the sphere (surface normals perpendicular to the viewing angle) will reflect more than the center of the sphere (surface normals parallel to the viewing angle).
In my NPR algorithms, this concept isn't used for anything to do with reflection. What the fresnel pass helps to do is define edges of geometry (where surface normals are perpendicular to the viewing angle). It's particularly useful because it's completely geometry based and doesn't take anything else into account (surface color or other properties, etc.).
3DL makes it relatively easy to write a custom shader that uses this concept to map how perpendicular surfaces are in relation to the viewing angle (black=perpendicular and white=parallel). This map is one way that the algos know where edges are.
It should be noted that this information is also contained in the red and green channels of a tangent space normal map.
HTH.
- Greg
In these background style explorations, the goal was to focus on color palettes and a loose feel with less detail than the character renderings posted earlier:
The last one of the forest is a hot mess! It's a complcated scene and the style definitely doesn't work in that case, but some of the line work it produced on the tree in the upper right-hand corner was interesting.
- Greg
algovincian Oh, I love how these look! Gorgeous background styles!
Thanks for taking the time to check them out @SapphireBlue - glad you like 'em! I'm pleased with the results, too, but fear that there may not be enough seperation when figures and other objects are added in the foreground. We shall see . . .
- Greg
Those are cool Greg! They look like watercolor paintings!
Thanks @3Diva! As feared, it's proven to be a struggle trying to find a way to render figures in the foreground with these BGs.
Stylistically, some tweaks have already been made that look ok, but there's an issue with the masking caused by partial opacity, and made worse by the simplification and smoothing algos. It's epecially noticeable on the ends of transmapped hair, so it's a common issue - no clue what to do about it . . . doh!
- Greg
I like the watercolor feel some of these have.
Maybe render the figures and the backgrounds separately? Would doing larger renders of the figures and separate from the background solve the issue?
The renders are already 20 megapixels - all resized down to the small images posted here. As far as rendering the figures and BGs separate goes, it's been tried both ways in the past. It's actually rendering them separately that's causing the issues with the mask. Ultimately, I'd like to use the figures as sprites so they need to be rendered separately with masks, though. The problem is that my wee-little pea brain is having trouble imagining exactly how to make that happen.
Here's a couple quick examples illustrating the issue:
It should be noted that the white halo effect is actually much worse than it appears in these images (the hair in both). For these, I cheated and rendered the figures with knowledge of the BG in an effort to minimize the issue. In order to produce the sprites, that won't be possible.
I ended up rendering the BG's at a lower resolution. The blacks were pulled up off the floor for the BG, and a bit of large radius gaussian blur was added to a duplicate BG layer set to darken. This helped to soften the BG and make the figures pop.
I'm beat from travelling and just got back, but I'll make a longer post about the issue when I'm able find some time. Hopefully, detailing exactly what's going on at the various stages of the algos will help shake a solution free!
- Greg
Thanks for taking the time to stop by and comment, @Rakuda. These painting algorithms are stuff I worked on many years, even decades, ago. Back then I applied them to straight 2D renders of 3D scenes or photos. Turns out that they look much better when they're applied using the additional 3D info contained in the render passes, and when applied to the already algo'd output.
- Greg
Here's a screencap of a simple test scene setup in DS:
It shows the basic setup for how the sprites will be used, and would be pretty much be the same for a game or motion comic, too.
A short animation with a panning camera was rendered out to illustrate the parallax effect, as well as the white halo issue on the hair:
The frames were rendered out at only 15fps, but interpolated frames were created to make a 1080p 60fps video to actually upload (which should help with compression efficiency making a smaller file size to stream). Hopefully, this will all make for a good looking video that plays back smoothly while saving some render time since the animation was only rendered at 15fps.
A few ideas have come to mind about how to fix the halo issue, too. With any luck, they'll pan out I'll upload the results this weekend (if it works lol).
- Greg
I'm sure that would help, but it would be a shame not to be able to use all of the fantastic trans-mapped hairs in my library. You may be right, though - I'm messing with the masks right now and although I have been able to improve the situation, it's still not where I'd like it to be.
Maybe it's time to switch gears for a little while and come back to it later!
- Greg
Do you have any Neftis hair? https://www.daz3d.com/neftis3d I find that with NPR work, many of their hair models work well for NPR with the trans maps removed altogether. Most of their modeled strands are already pretty thin and fine, even without the trans maps.
Pretty cool seeing other people's techniques in progress like that.
The hope is that the discussion sparks some ideas in other's minds - maybe even presents a different way of thinking about things and a new approach to solving problems. I know there are lots of lurkers who read without commenting, but it's always nice to get the confirmation, @vrba79, so thanks for that. As a bonus, discussing technical aspects usually helps to organize my thoughts and sometimes helps lead new to solutions.
And now for some pictures:
It's still not perfect, but the white halo has been drastically reduced as the drop shadows show. Several networks were trained in the hopes of using neural nets to get the job done with varying degrees of success. Unfortunately, there were always unintended consequences in the form of areas that got masked that should not have been, or areas that should be masked that were not.
In this case, the masks used to create these 2 images were still generated automatically, but using an iterative process designed by a human rather than so-called AI.
I'll keep working on trying to eliminate the last traces of white halo while avoiding any unintended consequences, but these results are a big improvement. Time to run some larger batches and make sure that the solution works in the general case - specifically including all sorts of trans-mapped hair, as well as some of the @Neftis3D hair that @3Diva mentioned (I've already bought 50+ from their store over the years).
- Greg
I'm so glad to hear you're making progress with the hair. I know that was bothering you. I never really noticed myself unless you pointed it out, but I know that as artists we tend to see things with our own art that others might not notice. The new images look great!
I look forward to seeing more of your experiments!
Here's a few more quick drop-shadow tests to see whether or not the refinement process for the masks is working as intended:
So far, so good - no halos!
It also served a test of a different scale of subject matter (face vs. full body vs. crowds), as well as pixel resolutions. It's always been challenging (for me, anyway) to deal with line thickness in different situations - especially knowing that the images are going to be resized, sharpened, etc. by different display devices in ways that aren't under your control.
- Greg
Couldn't resist letting a couple of renders cook of @Strangefate's upcoming new release, "Mad Love" as I worked today:
Let's hope there ends of being a bunch more like this one!
Fun to work with all of the goodies included with the set - you can check out the set in all of it's glory rendered in Iray here:
https://www.daz3d.com/forums/discussion/comment/7643811/#Comment_7643811
I don't want to get ahead of anything, but if you follow his thread, I'm sure there will be many more images to come as things progress.
- Greg
AHHHHH! That looks SO GOOD! The lines look so nice! The colors are great too - but there's something about the lines. I'm REALLY digging it! I don't know what you're doing but man those lines are great!